A Multimodal Dynamical Variational Autoencoder for Audiovisual Speech Representation Learning
Samir Sadok1 Simon Leglaive1 Laurent Girin2 Xavier Alameda-Pineda3 Renaud Séguier1
1CentraleSupélec, IETR UMR CNRS 6164, France
2Univ. Grenoble Alpes, CNRS, Grenoble-INP, GIPSA-lab, France
3Inria, Univ. Grenoble Alpes, CNRS, LJK, France
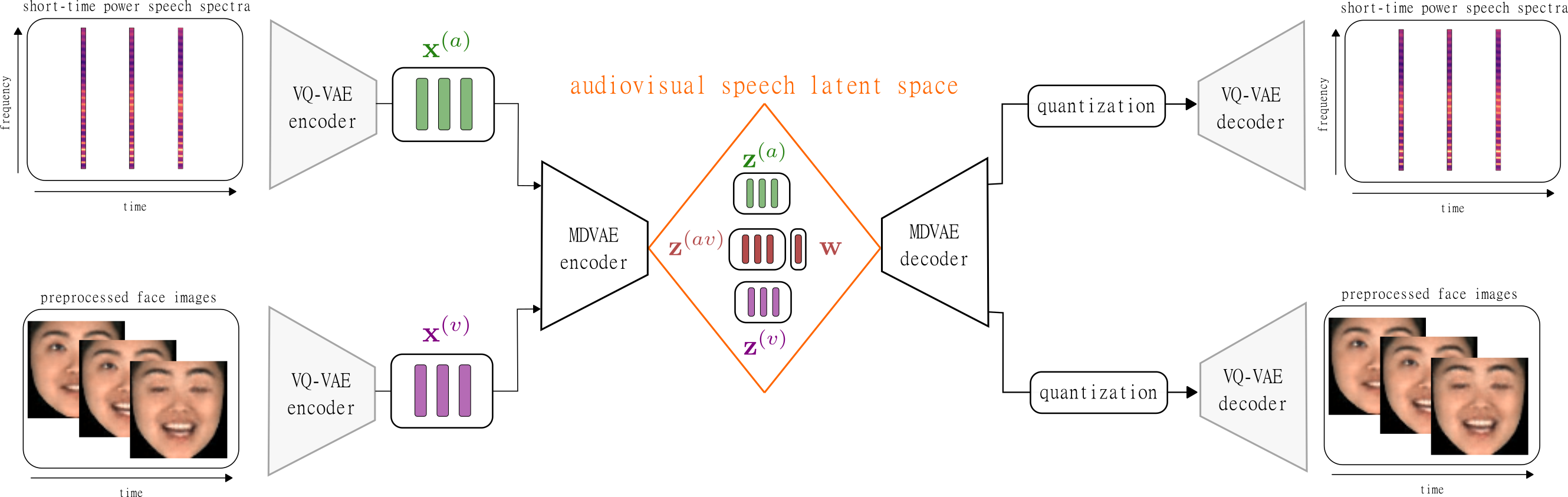
High-dimensional data such as natural images or speech signals exhibit some form of regularity, preventing their dimensions from varying independently. This suggests that there exists a lower dimensional latent representation from which the high-dimensional observed data were generated. Uncovering the hidden explanatory features of complex data is the goal of representation learning, and deep latent variable generative models have emerged as promising unsupervised approaches. In particular, the variational autoencoder (VAE) which is equipped with both a generative and inference model allows for the analysis, transformation, and generation of various types of data. Over the past few years, the VAE has been extended to deal with data that are either multimodal \textit{or} dynamical (i.e., sequential). In this paper, we present a multimodal \textit{and} dynamical VAE (MDVAE) applied to unsupervised audio-visual speech representation learning. The latent space is structured to dissociate the latent dynamical factors that are shared between the modalities from those that are specific to each modality. A static latent variable is also introduced to encode the information that is constant over time within an audiovisual speech sequence. The model is trained in an unsupervised manner on an audiovisual emotional speech dataset, in two stages. In the first stage, a vector quantized VAE (VQ-VAE) is learned independently for each modality, without temporal modeling. The second stage consists in learning the MDVAE model on the intermediate representation of the VQ-VAEs before quantization. The disentanglement between static versus dynamical and modality-specific versus modality-common information occurs during this second training stage. Extensive experiments are conducted to investigate how audiovisual speech latent factors are encoded in the latent space of MDVAE. These experiments include manipulating audiovisual speech, audiovisual facial image denoising, and audiovisual speech emotion recognition. The results show that MDVAE effectively combines the audio and visual information in its latent space. They also show that the learned static representation of audiovisual speech can be used for emotion recognition with few labeled data, and with better accuracy compared with unimodal baselines and a state-of-the-art supervised model based on an audiovisual transformer architecture.
|

|
We will present qualitative results obtained by reconstructing an audiovisual speech sequence using some of the latent variables from another sequence.
For the visual modality:
|
We transfer \(\mathbf{z}^{(v)}\) from the central sequence in red to the surrounding sequences. 
Only head and eye movements are transfered. |
We transfer \(\mathbf{z}^{(av)}\) from the central sequence in red to the surrounding sequences. 
Only lip movements are transfered. |
We transfer \(\mathbf{z}^{(v)}\) and \(\mathbf{z}^{(av)}\) from the central sequence in red to the surrounding sequences. 
All dynamical factors are transfered. |
|
Two original visual sequences. (Scroll left) the visual sequence of a man; (Scroll right) the visual sequence of a woman; 

|
|
We transfer \(\mathbf{z}^{(v)}\) from the background sequence to the foreground sequence. 
|
We transfer \(\mathbf{z}^{(av)}\) from the background sequence to the foreground sequence. 
|

|
|
|
We transfer \(\mathbf{z}^{(v)}\) and \(\mathbf{z}^{(av)}\) from the background sequence to the foreground sequence. 
|

|
For the audio modality:
|
\(\mathbf{z}^{(a)}\) and \(\mathbf{z}^{(av)}\) are fixed, \(\mathbf{w}\) varies. 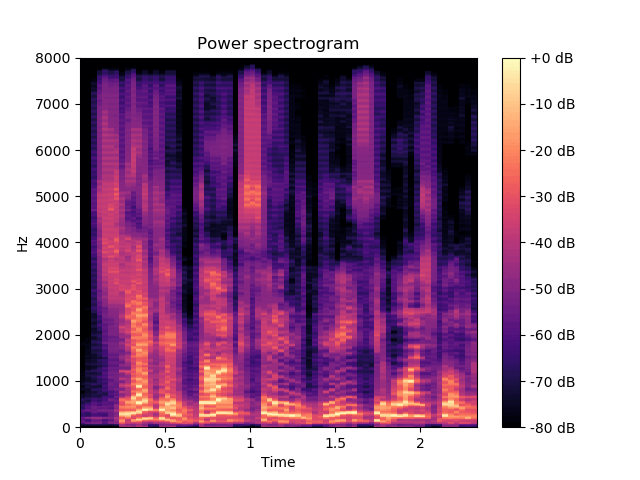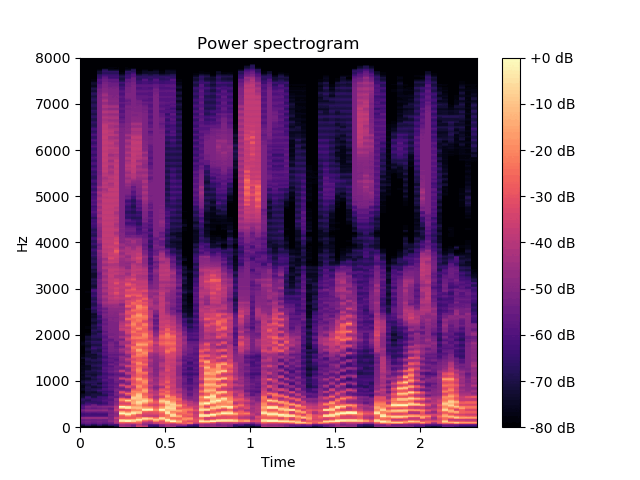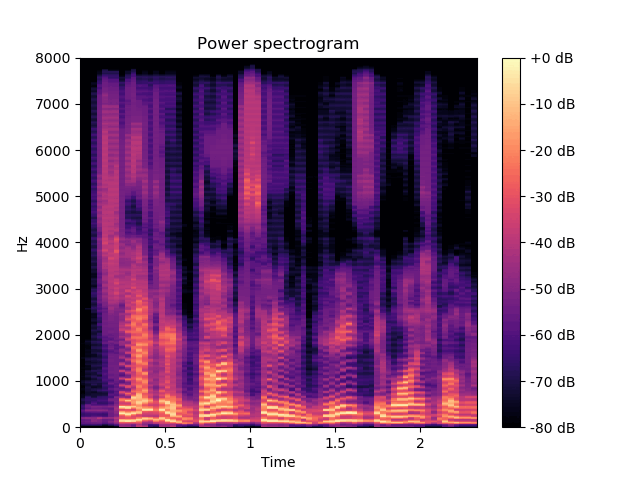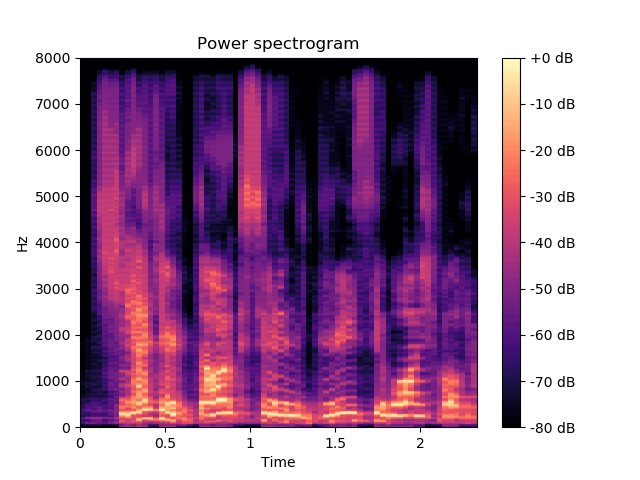
\(\mathbf{w}\) seems to encode the speaker's audio identity. |
\(\mathbf{w}\) and \(\mathbf{z}^{(av)}\) are fixed, \(\mathbf{z}^{(a)}\) varies. 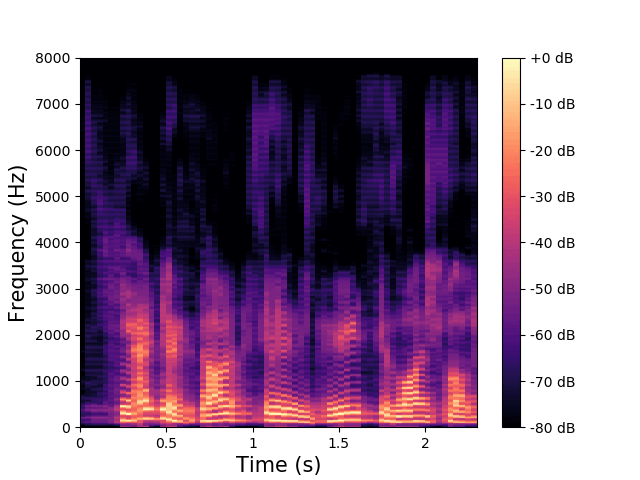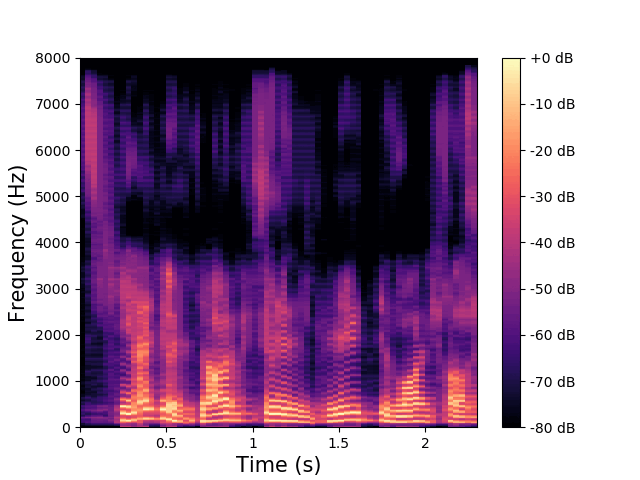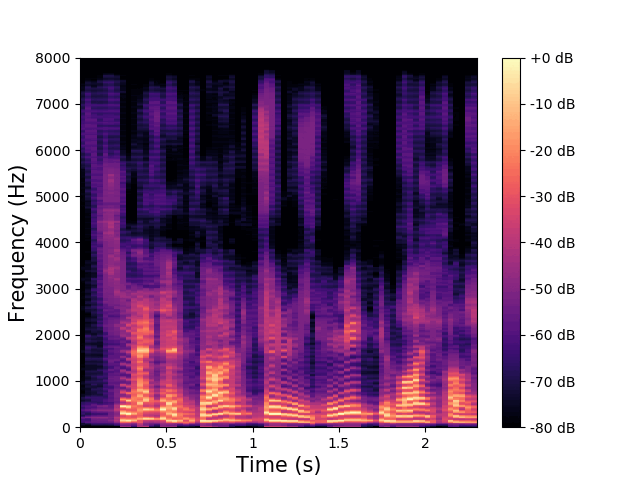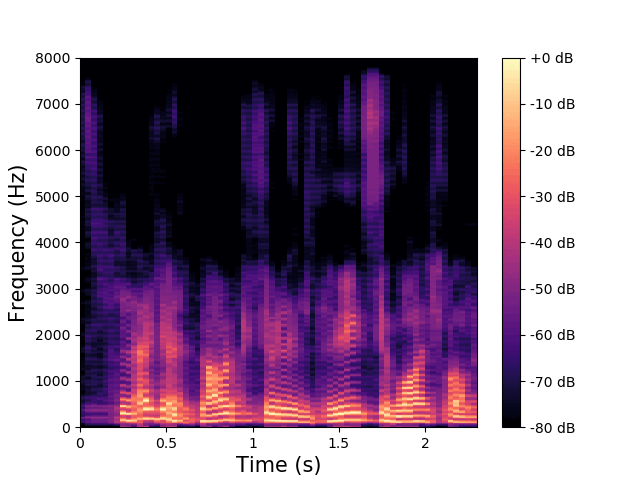
\(\mathbf{z}^{(v)}\) encodes the high-frequency phonemic content. |
\(\mathbf{z}^{(a)}\) and \(\mathbf{w}\) are fixed, \(\mathbf{z}^{(av)}\) varies. 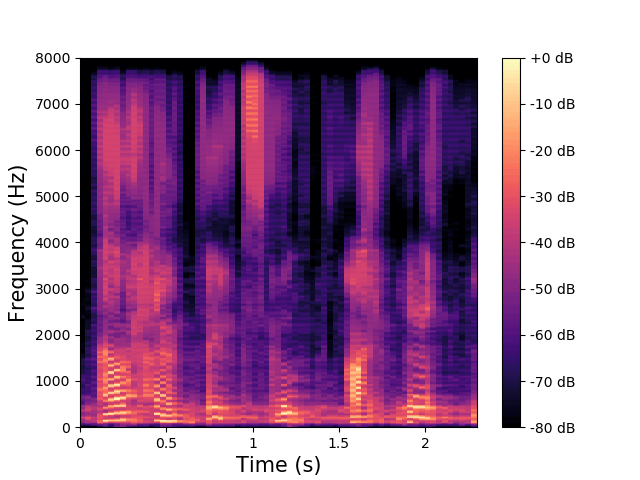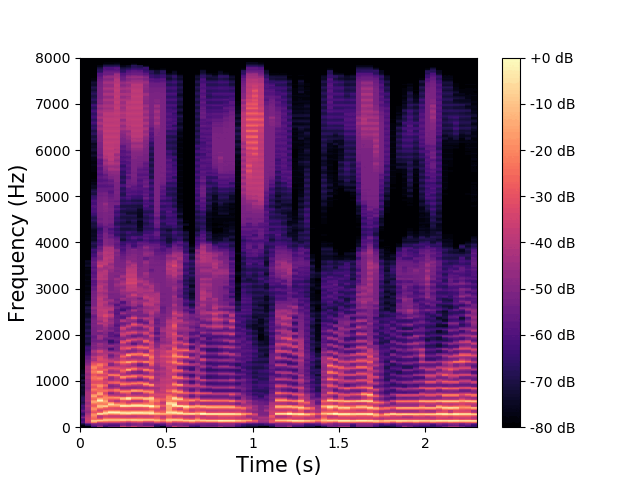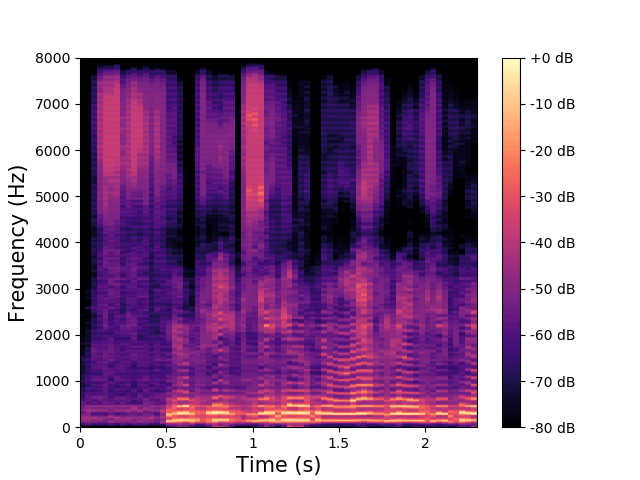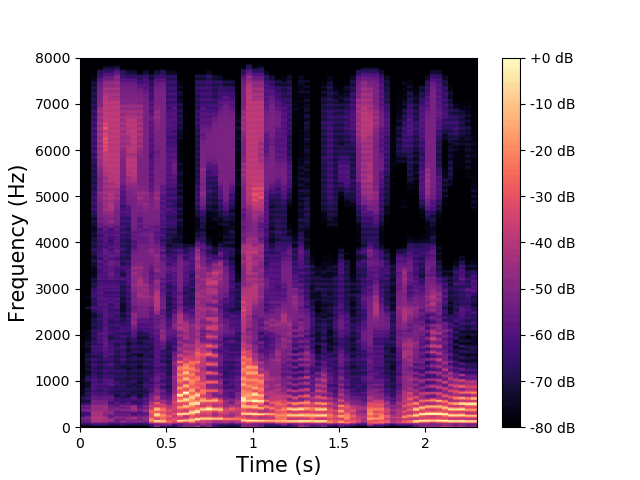
\(\mathbf{z}^{(av)}\) encodes the low-frequency phonemic content. |
|
Same emotion, different identities. |
Same identity, different emotions. |
|
Scroll right to change the identity in a smooth way, keeping the emotion; 

|
Scroll right to change the emotion in a smooth way, keeping the identity; 

|
|
|
|
We illustrate the ability of the MDVAE model to generate speech spectrograms with a qualitative example. Figures belows show spectrograms generated by sampling according to the prior distribution of \(\mathbf{z}^{(av)}\) and \(\mathbf{z}^{(a)}\) , conditioned on the first thirty frames. These first thirty frames (with a duration of 1s) are obtained through analysis-resynthesis. After 1s, we switch the MDVAE to pure generation mode. We can see that the spectrograms generated with the prior distribution of \(\mathbf{z}^{(av)}\) exhibit a harmonic structure.
|
Example of speech power spectrogram reconstructed (0-1 s) and generated (1-2.6 s) by a MDVAE model. 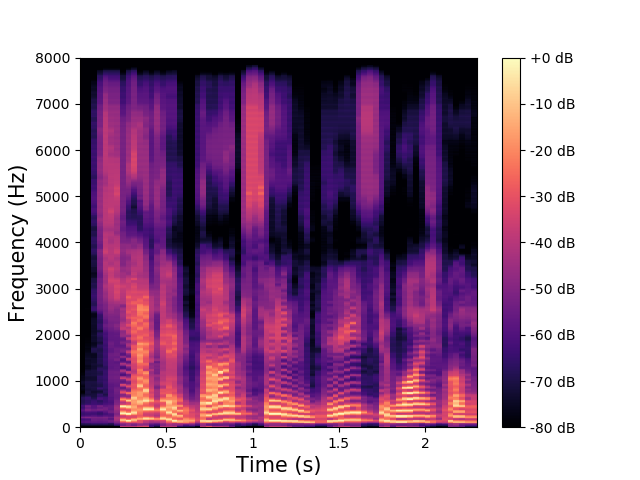
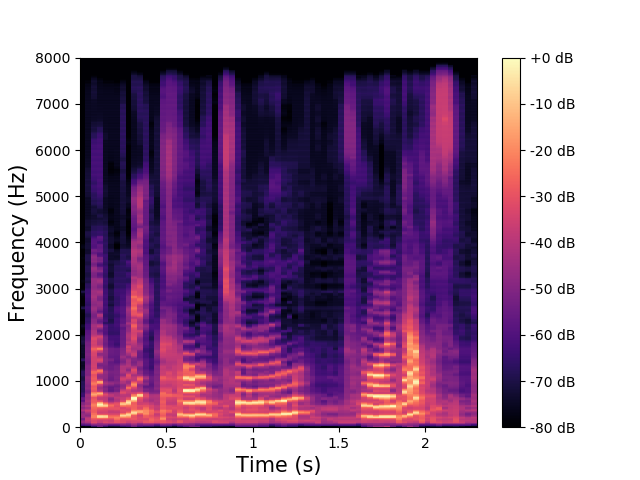
|
Example of speech power spectrogram reconstructed (0-1 s) and generated (1-2.6 s) by a MDVAE model.
|
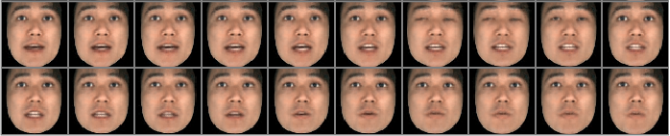
Similarly, we illustrate the ability of the MDVAE model to generate visual frames with a qualitative example. Figure below illustrate this by sampling following the Gaussian prior of \(\mathbf{z}^{(v)}\) and \(\mathbf{z}^{(av)}\) , conditioned on the analyzed-resynthesized first frame of the sequence. This strategy of conditioning to the first frame, allows the generation mode to have temporally coherent sequences. The first lightened lines correspond to the original visual sequences, and the other lines are three different generations. As expected, we have a smooth transition from the analyzed-resynthesized frame to the generated one.
|
Original sequence. 
Generated sequence.
|
Original sequence. 
Generated sequence.
|